Smartphone Brand Preferences Example¶
This example highlights the most important features smartphones from certain brands have, to predict the most likely smartphone-brand purchase. The Smartphone Brand Preferences Dataset is used to capture the characteristics a smartphone has and
why people choose to buy a determined brand
This dataset can be obtained using the load_phone_brand_preferences()
function:
>>> from xaiographs.datasets import load_phone_brand_preferences
>>> df_dataset = load_phone_brand_preferences()
>>> df_dataset.head(5)
brand internal_memory performance main_camera selfie_camera battery_size screen size weight price age gender occupation
0 Samsung 128 8.81 50 10 3700 6.1 167 528 38 Female Data analyst
1 Apple 256 7.94 12 12 3065 6.1 204 999 38 Female Data analyst
2 Google 128 6.76 50 8 4614 6.4 207 499 31 Female sales
3 Samsung 128 7.22 50 10 4500 6.6 195 899 31 Female sales
4 Google 128 6.88 12 8 4410 6.1 178 449 27 Female Team leader
To determine the explainability of this dataset, XAIoGraphs provides a dataset that has already been discretized and
columns with targets probabilities using
load_phone_brand_preferences_discretized() function:
>>> from xaiographs.datasets import load_phone_brand_preferences_discretized
>>> df_dataset, features_cols, target_cols, y_true, y_predict = load_phone_brand_preferences_discretized()
>>> df_dataset.head(5)
id internal_memory performance main_camera selfie_camera battery_size screen_size weight price age gender occupation y_true y_predict Apple Google Motorola Samsung Xiaomi
0 0 128_GB Ultra top 15_50_MP <10_MP <4000_mAh <6.4_inches <190_g 450_700_dollars 35_45_years Female Technology Samsung Apple 1 0 0 0 0
1 1 >=256_GB Top <15_MP 10_30_MP <4000_mAh <6.4_inches 190_205_g >700_dollars 35_45_years Female Technology Apple Apple 1 0 0 0 0
2 2 128_GB Mid 15_50_MP <10_MP 4000_4700_mAh <6.4_inches >205_g 450_700_dollars 25_35_years Female Business Google Google 0 1 0 0 0
3 3 128_GB Mid 15_50_MP <10_MP 4000_4700_mAh 6.4_6.6_inches 190_205_g >700_dollars 25_35_years Female Business Samsung Samsung 0 0 0 1 0
4 4 128_GB Mid <15_MP <10_MP 4000_4700_mAh <6.4_inches <190_g 200_450_dollars 25_35_years Female Administration Google Google 0 1 0 0 0
Code Example¶
The following entry point (with Python virtual environment enabled) is used to demonstrate this example.
>> smartphone_brand_preferences
Alternatively, you may run the code below to view a full implementation of all XAIoGraphs functionalities with this Dataset:
from xaiographs import Explainer
from xaiographs import Why
from xaiographs import Fairness
from xaiographs.datasets import load_phone_brand_preferences_discretized, load_phone_brand_preferences_why
LANG = 'en'
# LOAD DATASETS & SEMANTICS
df_phone_brand_pref, feature_cols, target_cols, y_true, y_predict = load_phone_brand_preferences_discretized()
df_values_semantics, df_target_values_semantics = load_phone_brand_preferences_why(language=LANG)
# EXPLAINER
explainer = Explainer(importance_engine='LIDE', verbose=1)
explainer.fit(df=df_phone_brand_pref, feature_cols=feature_cols, target_cols=target_cols)
# WHY
why = Why(language=LANG,
explainer=explainer,
why_values_semantics=df_values_semantics,
why_target_values_semantics=df_target_values_semantics,
verbose=1)
why.fit()
# FAIRNESS
f = Fairness(verbose=1)
f.fit(df=df_phone_brand_pref[feature_cols + [y_true] + [y_predict]],
sensitive_cols=['gender', 'age'],
target_col=y_true,
predict_col=y_predict)
XAIoWeb Smartphone Brand Preferences¶
After running the .fit() methods of each of the classes (one, two, or all three), a sequence of JSON files are
generated in the xaioweb_files folder to visualized in XAIoWeb interface.
To launch the web (with the virtual environment enabled), run the following entry point:
>> xaioweb -d xaioweb_files -o -f
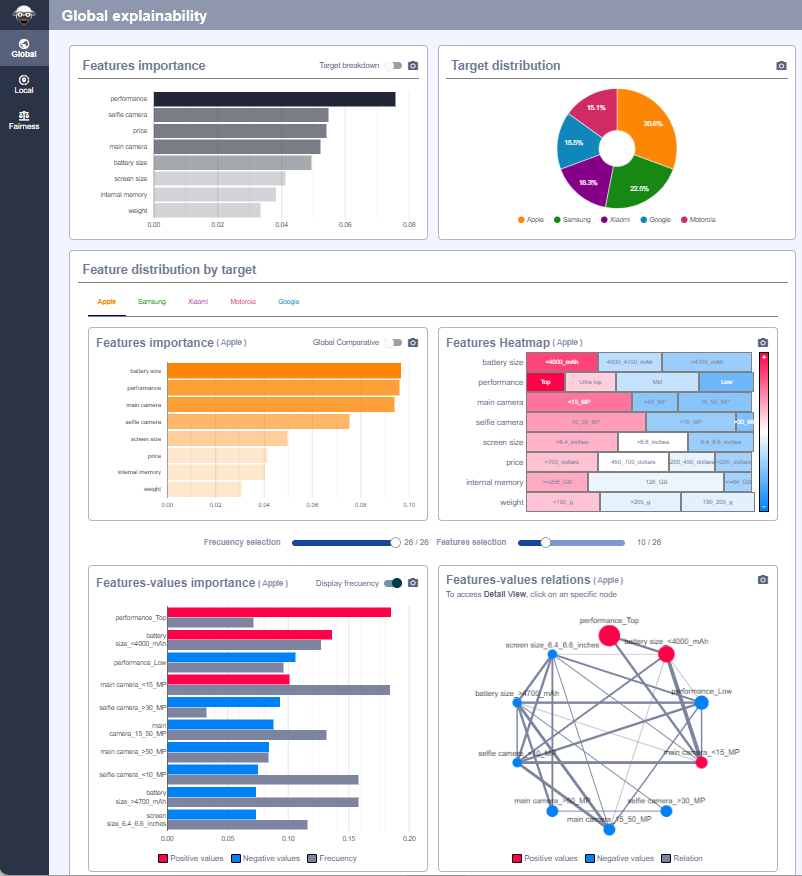
And the results seen in XAIoWeb are the following:
Global Explainability¶
Local Explainability¶

Fairness¶
